TOM: Text-to-Object Mapping for Library Bookshelves
As part of the Freshman Research Initiative, we decided to build a system that would assist libraries at UT by utilizing Building-Wide Intelligence robots supplemented with a camera module. We built an easy-to-use vision system that allowed robots to easily recognize where a particular book is located on a particular bookshelf.
Alongside a group that worked on navigating to the general vicinity of a particular book in a library and turning toward it, our project enabled the easy use of these robots for book retrieval in libraries, offices, and other physical file/book storage locations throughout the world.
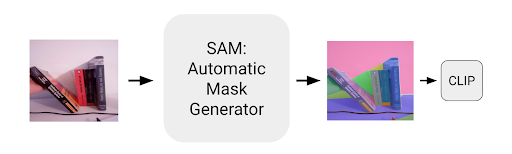
Our solution utilized CLIP by OpenAI, Meta’s Segment Anything Model, and Google Cloud’s Vision system to easily segment and identify the pixels that belonged to a particular book simply given the name of the book. The overall system is visualized below.
We first use Meta’s foundational model for segmentation tasks to perform segmentation on our bookshelf image and determine where the segments are.
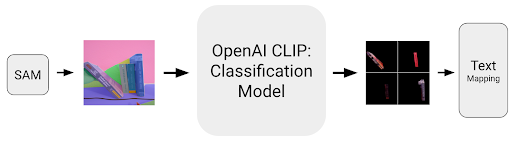
Then, we use OpenAI’s CLIP model to determine which of the generated masks are actually books and which ones are not.
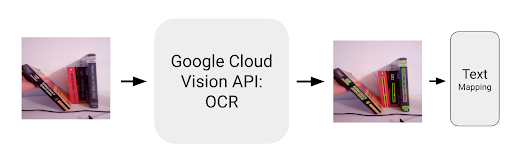
We use Google Cloud’s Vision API to detect all text in an image and the location of the bounding boxes for each of these text pieces.
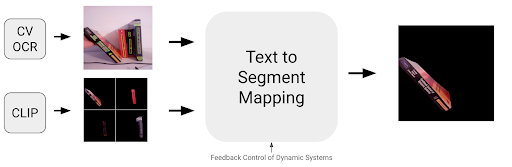
Finally, we use Google’s Tesseract and vision transformer backed vision API to generate bounding boxes for text locations and map the location to the correct physical segment.
Check out our paper for more information!